基于深度学习的文本分类研究(任务书,开题报告,论文12000字)
摘要
如何从大量的文本信息中获取有价值的信息,已经成为自然语言处理领域的关键问题。传统的文本分类方法主要以浅层机器学习为主,不仅忽略了语义信息,还会因为高维性的特征导致难以利用。由于深度学习的快速发展在图像识别,语音识别等方面有重大突破,因此本文是基于深度学习的卷积神经网络模型对文本分类问题进行研究。
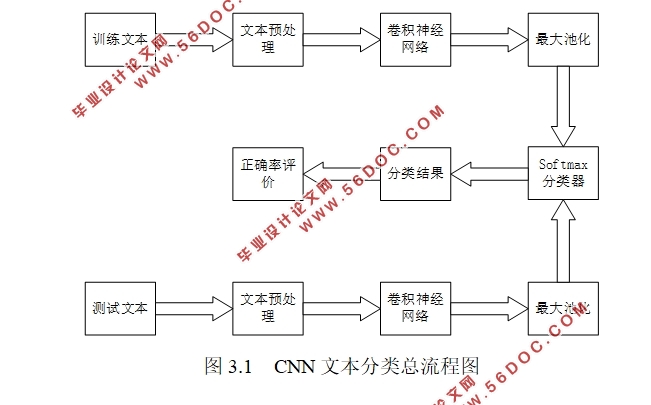
本文主要研究了文本表示方法和卷积神经网络模型。在文本表示方面采用当前广泛应用的词向量表示法,在此之前需要先对文本进行分词,去掉不用的词,构建了一个词汇表。接下来利用卷积神经网络模型训练来得到词向量,在模型中主要包括输入层、卷积层、池化层及全连接层。这些层是对文本的特征提取,是为了最终得到文本特征的最优表示。模型中重要的卷积层,通过带有权重的卷积核与输入的特征销量卷积的到局部特征。在经过池化层中的最大池化,当文本内容发生变化时,仍然能够准确的到原本的特征。卷积层和池化层都能够在一定程度损失不重要的信息达到降维的效果,并且能够把文本的基本语义信息完整的保存,基于该模型的文本分类的准确率更高。
经过本次研究的具体操作,实验结果表明:基于卷积神经网络模型的分类具有很高的分类效果,对于10个分类的数据集,正确率达到很高,误差较小。
关键词:文本分类;词嵌入;深度学习;卷积神经网络模型
Abstract
How to obtain valuable information from a large amount of text information has become a key issue in the field of natural language processing. Traditional text classification methods are mainly based on shallow machine learning, which not only ignores semantic information, but also makes it difficult to use due to high-dimensional features. With the rapid development of depth learning, it has made great breakthroughs in image recognition and speech recognition. Therefore, this paper studies text classification based on convolution neural network model of depth learning.
This paper mainly studies the text representation method and convolution neural network model. In terms of text representation, the currently widely used word vector representation method is adopted. Before this, the text needs to be segmented, unused words are removed, and a vocabulary is constructed. Next, the convolution neural network model training is used to obtain word vectors, which mainly include input layer, convolution layer, pooling layer and full connection layer. These layers are feature extraction of text, in order to obtain the optimal representation of text features. The important convolution layer in the model convolves the weighted convolution kernel with the input feature sales volume to local features. After the maximum pooling in the pooling layer, when the text content changes, the original features can still be accurately obtained. Both convolution layer and pooling layer can lose unimportant information to a certain extent to achieve the effect of dimension reduction, and can completely save the basic semantic information of the text. The text classification accuracy based on this model is higher.
After the specific operation of this study, the experimental results show that the classification based on the convolution neural network model has a high classification effect. For 10 classified data sets, the accuracy rate is very high and the error is small.
Key Words:Text Classification;Word Vector;Depth Learning,;Convolution Neural Network
目录
第1章绪论 1
1.1 研究背景及意义 1
1.1.1 研究背景 1
1.1.2 研究意义 1
1.2 研究现状 2
1.2.1 文本表示 2
1.2.2 文本分类 2
1.2.3 深度学习 3
1.3 本文主要工作 3
1.4 论文结构 3
第2章相关技术 4
2.1 文本表示技术 4
2.1.1 布尔逻辑模型 4
2.1.3向量空间模型(VSM) 4
2.1.4 word embedding 4
2.2 文本分技术 6
2.3本章总结 7
第3章分类模型 8
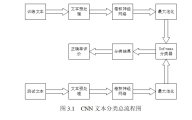
3.1 中文文本分类 8
3.2 文本预处理 8
3.3卷积神经网络模型研究 9
3.3.1 输入层 10
3.3.2 卷积层 10
3.3.3 池化层 11
3.3.4 全连接层 12
3.4本章小结 13
第4章实验结果与分析 14
4.1 实验环境设置 14
4.2 文本预处理结果 14
4.3模型训练 14
4.4 测试的结果及分析 16
4.5 文本预测 17
4.6 对比分析 18
4.7 本章小结 21
第5章总结与展望 22
5.1 工作总结 22
5.2 展望 22
参考文献 24
|